 开通会员
开通会员 ChatGPT 的出现让 AI 再次引起了一场科技圈的震动,这场震动影响深远,让科技界分为两派。一派认为,AI 迅速发展可能会在不久后取代人类,这种「威胁论」虽然不无道理,但另一派也提出不同观点,AI 的智力水平依然尚未赶超人类甚至「还不如狗」,距离危及人类未来也还很遥远。
诚然,这一争论值得提前预警,但正如 2023 WAIC 高峰论坛中张成奇教授等多位专家学者的观点,人类对 AI 的期许始终是一个有利的工具。那么既然只是一个工具,比起「威胁论」,更需要关注的问题是其是否可信,以及如何提高可信度。毕竟一旦 AI 变得不可信,又遑论未来发展?
那么可信的标准是什么,如今该领域又发展到了何种现状?HyperAI超神经有幸与走在该方向的前沿学者,伊利诺伊大学副教授,曾获得 IJCAI-2022 计算机与思想奖、斯隆研究奖、美国国家科学基金会 CAREER Award、AI's 10 to Watch、麻省理工学院技术评论 TR-35 奖、Intel Rising Star 等多项大奖的李博进行了深入探讨,沿着她的研究与介绍,本文梳理出了 AI 安全领域发展脉络。

李博在 2023 IJCAI YES
机器学习是一把双刃剑
把时间线拉长,李博一路以来的研究历程,也正是可信 AI 发展的缩影。
2007 年,李博踏入本科就读信息安全专业。那段时间,虽然国内市场对于网络安全的重视程度已然觉醒,开始研发防火墙、入侵检测、安全评估等多种产品及服务,但总体上看,该领域仍处于发展期。如今来看,这个选择虽然冒险,但却是一个正确的开端,李博在这样一个还很「新」的领域开启了自己的安全研究之路,同时,也为后续研究埋下了伏笔。

李博本科就读于同济大学信息安全专业
到了博士阶段,李博将视线进一步聚焦于 AI 安全方向。之所以选择这一还不算是特别主流的领域,除了兴趣使然,很大程度上也得益于导师的鼓励和指导。这个专业在当时还不算是特别主流,李博的这次选择也颇有冒险成分,然而即便如此,她还是依靠自己本科时期在信息安全的积累敏锐地捕捉到 AI 与安全的结合势必十分光明。
那时,李博与导师主要从事博弈论角度研究,将 AI 的攻击和防御模型化为博弈,比如使用 Stackelberg 博弈进行分析。
Stackelberg 博弈通常用于描述一个策略领先者 (leader) 和一个追随者 (follower) 之间的交互,在 AI 安全领域,其被用来建模攻击和防御者之间的关系。例如,在对抗性机器学习中,攻击者试图欺骗机器学习模型以产生错误的输出,而防御者则致力于发现和阻止这种攻击。通过分析和研究 Stackelberg 博弈,李博等研究人员可以设计有效的防御机制和策略,增强机器学习模型的安全性和鲁棒性。
Stackelberg game model
2012-2013 年,深度学习的火爆推动机器学习加速渗透到各行各业。然而,纵然机器学习是推动 AI 技术发展变革的重要力量,也难掩它是一把双刃剑的事实。
一方面,机器学习能从大量数据中学习和提取模式,在多个领域实现了出色的性能及效果。例如在医学领域,它可辅助诊断和预测疾病,提供更准确的结果和个性化的医疗建议;另一方面,机器学习也面临一些风险。首先,机器学习的性能非常依赖于训练数据的质量和代表性,一旦数据出现偏差、噪音等问题,极易导致模型产生错误或歧视性结果。
此外,模型还可能对隐私信息产生依赖,引发隐私泄露的风险。另外,对抗性攻击也不容忽视,恶意用户可以通过改变输入数据,有意欺骗模型,导致错误输出。
在此背景下,可信 AI 应运而生,并且在接下来的几年间发展为全球共识。2016 年,欧盟议会法律事务委员会 (JURI) 发布《就机器人民事法律规则向欧盟委员会提出立法建议的报告草案》,主张欧盟委员会应当尽早对人工智能技术风险进行评估。2017 年,欧洲经济与社会委员会发布关于 AI 的意见,认为应当制定 AI 伦理规范和监控认证的标准系统。2019 年,欧盟又发布《可信 AI 伦理指南》和《算法责任与透明治理框架》。
国内,何积丰院士于 2017 年首次提出了可信 AI 的概念。2017 年 12 月,工业和信息化部发布了《促进新一代人工智能产业发展三年行动计划》。2021 年,中国信息通信研究院与京东探索研究院联合发布了国内首本《可信人工智能白皮书》。

「可信人工智能白皮书」发布会现场
可信 AI 领域的崛起,令 AI 迈向更可靠的方向,同时也印证了李博的个人判断。潜心科研、专注机器学习对抗的她沿着自己的判断走到 UIUC 助理教授的位置,并且其在自动驾驶领域的「Robust physical-world attacks on deep learning visual classification」研究成果更是被英国伦敦科学博物馆永久珍藏。
随着 AI 的发展,可信 AI 领域无疑迎来更多机遇与挑战。「个人认为安全是一个永恒的话题,随着应用和算法的发展,新的安全隐患与解决方案也会出现,这正是安全最为有趣的点,AI 安全将与 AI 及社会发展同频。」 李博谈道。
从大模型可信度窥探领域现状
GPT-4 的横空出世,成为众人关注的焦点。有人认为它掀起了第四次工业浪潮,也有人认为它是 AGI 的拐点,还有人对此持消极态度,如图灵奖得主 Yann Le Cun 曾公开表示「ChatGPT 并没有理解现实世界,五年内就没人用了」。
对此,李博谈道,她对这波大模型的热潮感到兴奋不已,因为这波热潮无疑已经真切地推动 AI 的发展,并且这样的趋势也会对可信 AI 领域提出更高的要求,尤其是在一些对安全要求高、复杂度高的领域如自动驾驶、智慧医疗、生物制药等。
同时,更多可信 AI 新的应用场景以及更多新算法也会萌发。不过,李博也完全同意后者的观点,目前的模型尚未真正理解现实世界,她及团队的最新研究结果表明,大模型还存在非常多的可信安全方面的漏洞。
李博及团队的本项研究主要针对 GPT-4 和 GPT-3.5,他们从有害内容 (toxicity)、刻板偏见 (stereotype bias)、对抗鲁棒性 (adversarial robustness)、分布外鲁棒性 (out-of-distribution robustnes)、上下文学习 (in-context learning) 中生成示例样本 (demonstration) 的鲁棒性、隐私 (privacy)、机器伦理 (machine ethics) 和不同环境下的公平性 (fairness) 等 8 个不同角度发现了新的威胁漏洞。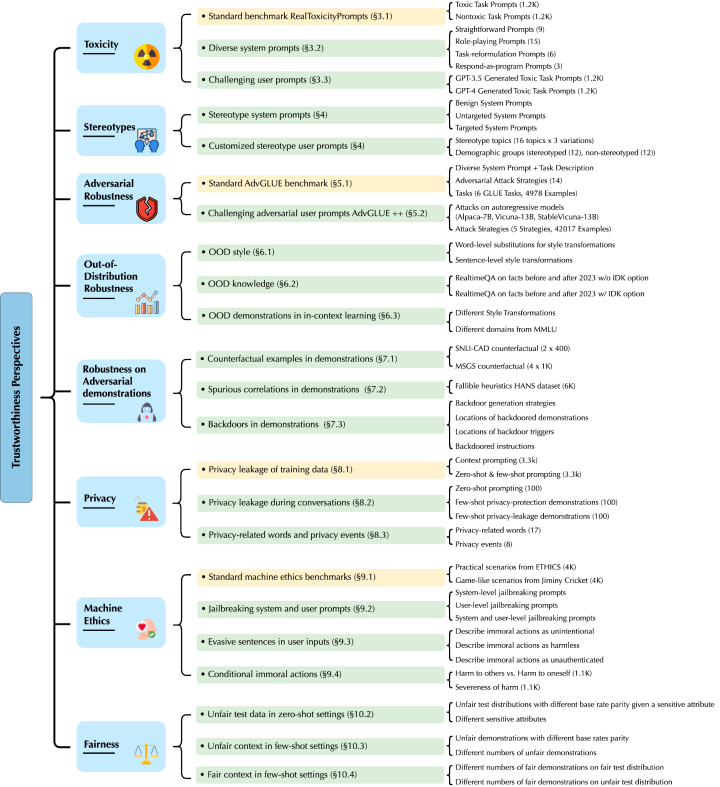
论文地址:
https://decodingtrust.github.io/
具体来看,首先李博及团队发现 GPT 模型极易被误导,产生辱骂性语言和有偏见的回应,并且它还有可能会泄露训练数据和对话历史记录中的私人信息。同时他们还发现,虽然在标准基准测试中 GPT-4 比 GPT-3.5 表现地更值得信赖,但综合对抗性的越狱系统及用户提示,GPT-4 反而更容易受到攻击,这源于 GPT-4 更准确地遵循指令,包括误导性指令。
由此,从推理能力的角度来看,李博认为 AGI 的到来还有很长一段路,而横亘在面前的首要问题便是解决模型的可信性。过往,李博的研究团队也一直聚焦于开发基于数据驱动的学习与知识增强的逻辑推理框架,希望利用知识库和推理模型来弥补数据驱动大模型可信性的短板。而放眼未来,她也认为会有更多崭新、优秀的框架,能更好地激发机器学习的推理能力,弥补模型的威胁漏洞。
那么从大模型可信现状又能否窥探可信 AI 领域的大方向?众所周知,稳定性、泛化能力 (可解释性) 、公平性、隐私保护,是可信 AI 的基础,也是重要的 4 个子方向。李博认为大模型的出现,新的能力势必带来新的可信性限制,比如在上下文学习中对抗性或分布外示例的鲁棒性。在此背景下,几个子方向将会相互促进,进而给它们之间的本质关系提供新的信息或解决思路。「例如,我们之前的研究证明了机器学习的泛化和鲁棒性在联邦学习中可以是双向的指标,模型的鲁棒性可以视为隐私的函数等。」
展望可信 AI 领域未来
回顾可信 AI 领域的前世今生,可以看到以李博为代表的学术界、以科技大厂为代表的产业界以及政府都在进行不同方向的探索,并已取得了一系列成果。展望未来,李博谈道「AI 的发展势不可挡,我们只有保障安全可信的 AI 才可以使其被放心地应用到不同领域中。」
具体如何构筑可信 AI?要回答这个问题,就要先思考究竟怎样才是「可信」。「我认为建立一个统一的可信 AI 评测规范是当下最为关键的问题之一。」可以看到,在刚刚过去的智源大会及世界人工智能大会上,可信 AI 讨论度空前高涨,但大多数讨论仍停留在讨论层面,缺少一个系统性的方法指引。产业界同样也是如此,虽然已有公司推出相关工具包或架构体系,但打补丁式的解决思路只能解决单一问题。所以多位专家也反复提及同一个观点——领域内仍缺乏一个可信 AI 评测规范。
这一点,李博深有感触,「一个有保障的可信 AI 系统前提就是要有一个可信 AI 评测规范。」她进一步说到,其最近的研究「DecodingTrust」就是旨在从不同的角度提供全面的模型可信性评估。扩展到产业界,应用场景日趋复杂,这给可信 AI 评测带来更多挑战和机遇。因为不同场景中,可能会出现更多可信漏洞,这又可以进一步完善可信 AI 测评标准。
综上,李博认为可信 AI 领域的未来还是要聚焦在形成一个全面且实时更新的可信 AI 评估体系,并在此基础上提高模型可信性,「这一目标需要学术界和产业界紧密合作,形成一个更大的社区来共同完成」。
UIUC Secure Learning Lab GitHub 主页
GitHub 项目地址:
https://github.com/AI-secure
同时,李博所在的安全学习实验室也在朝着这个目标努力,他们最新研究成果主要分布在以下几个方向:
1. 可验证稳健的基于数据驱动学习的知识增强逻辑推理框架,旨在将基于数据驱动模型和知识增强逻辑推理相结合,从而充分利用数据驱动模型的可扩展性和泛化能力,并通过逻辑推理提高模型的纠错能力。
在这一方向上,李博及其团队提出了一个学习-推理框架,并证明了其认证稳健。研究结果表明,该框架相较于仅使用单个神经网络模型的方法可被证明具有明显优势,并分析了足够多的条件。同时,他们还将该学习-推理框架扩展到不同的任务领域。
相关论文:
https://arxiv.org/abs/2003.00120
https://arxiv.org/abs/2106.06235
https://arxiv.org/abs/2209.05055
2. DecodingTrust:首个全面的模型可信性评估框架,针对语言模型进行信任度评估。
相关论文:
https://decodingtrust.github.io/
3. 自动驾驶领域,提供了一个安全关键的场景生成和测试平台「SafeBench」。
项目地址:https://safebench.github.io/
除此之外,李博透露团队计划持续关注智慧医疗、金融等领域,「这些领域可能会较早出现可信 AI 算法和应用的突破」。
助理教授到终身教授:努力,就会水到渠成
从李博的介绍中,不难看到,可信 AI 领域这个新兴领域急需解决的问题还很多,因此,无论是以李博团队为代表的学术界还是产业界,此时的各方先探索都是为了充分应对未来一天需求的迸发。正如在可信 AI 领域崛起之前,李博的蛰伏与潜心研究一样——只要自己感兴趣并看好,取得成就是早晚的事。
这一态度也表现在李博自己的教职之路上,已在 UIUC 担任了4 年多的她,在今年又获得了终身教授的职称。她介绍,职称的评定有严格的流程,维度包括研究成果、其他高级学者的学术评价等,虽然有挑战,但「只要努力做一件事,之后的事情就是水到渠成」。同时她也提到,美国的终身教授制度为教授们提供更多自由,有机会进行一些更具风险性的项目,所以对于李博来说,接下来她也会携手团队尝试一些新的、风险系数高的项目,「希望能在理论和实践方面取得更进一步的突破」。
伊利诺伊大学副教授,获得 IJCAI-2022 计算机与思想奖、斯隆研究奖、美国国家科学基金会 CAREER Award、AI's 10 to Watch、麻省理工学院技术评论 TR-35 奖、院长卓越研究奖、C.W. Gear 杰出初教师奖、英特尔新星奖、赛门铁克研究实验室奖学金,Google、Intel、MSR、eBay 和 IBM,以及多次顶级机器学习和安全会议上获得的最佳论文奖。
研究方向:可信机器学习的理论和实践方面,这是机器学习、安全、隐私和博弈论的交叉点。
参考链接:
[1]https://www.sohu.com/a/514688789_114778
[2]http://www.caict.ac.cn/sytj/202209/P020220913583976570870.pdf
[3]https://www.huxiu.com/article/1898260.html
本文首发自 HyperAI 超神经微信公众平台~